链接
-
论文
-
代码
直觉
-
传统微调需要调整整个模型的参数,并且为每个任务都存储一个模型的参数,带来的开销大
-
Prefix tuning: 对自然语言生成任务,将语言模型参数冻结,转为优化一个小的,任务导向的连续向量(continuous task-specific vectors, 称为prefix)
相关工作
-
lightweight fine-tuning
-
关键的挑战是识别模型中蕴含的高性能架构和要调优的预训练参数子集。
prefix tuning的训练参数要比lightweight tuning还要少上30x倍
-
-
GPT-3: prompt, in-context learning
- 使用人工设计的prompts
模型结构
-
对自回归LM结构,采用 $z=[\text{Prefix}; x; y]$的方式, 对于encoder-decoder结构,采用 $z=[\text{Prefix}; x; \text{Prefix'}, y]$的方式
- 自回归$y$的生成是一个字一个字的生产,而其输入的$y$是先前生成的$y$,例如生成“天气好真开心”,生成到“心”时,模型的输入$y$为"天气好真开“
- prefix tuning在模型的每层都加了prefix参数
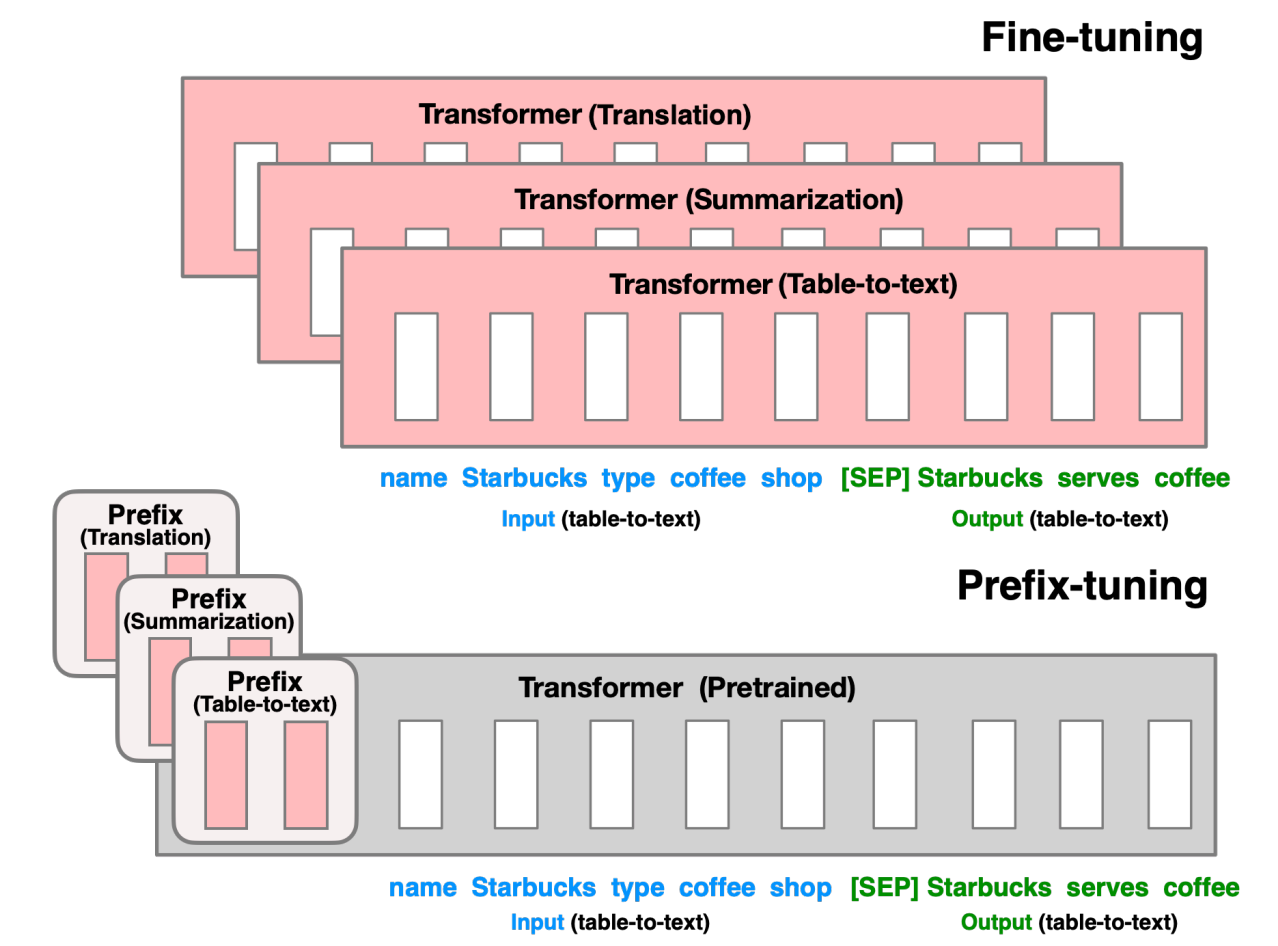
训练策略
-
prefix可以看做是一些虚拟的输入tokens, 语言模型(transformer)可以对这些虚拟tokens也做attention,但是这些prefix的参数与真实token的参数是完全独立的,而prefix的参数量相对真实token的参数量是极少的(比fine-tuning的存储参数少1000x倍)
-
对于不同任务,只需要使用一个LM模型,然后训练一个单独的prefix即可
-
prefix不是离散的tokens,而是看当做连续的词嵌入来优化
-
prefix tuning初始化一个可训练的参数矩阵,用于存储prefix向量参数
- 直接优化prefix矩阵会对学习率和初始化参数的选择非常敏感
-
为稳定优化过程和效果,再将prefix矩阵做重参数化(reparametrize)
- 直接优化Prompt参数不太稳定,加了个更大的MLP,训练完只保存MLP变换后的参数
-
-
使用AdamW, 线性学习率衰减策略(linear-learning rate scheduler)
数据集
-
table2text
- 数据集:E2E,WebNLG,DART
- 评估指标:BLEU, METEOR, TER, Mover-Score,BERT, BLEURT,
-
摘要
- 数据集:XSum
- 评估指标: ROUGE-1, ROUGE-2, ROUGE-L
实验效果
-
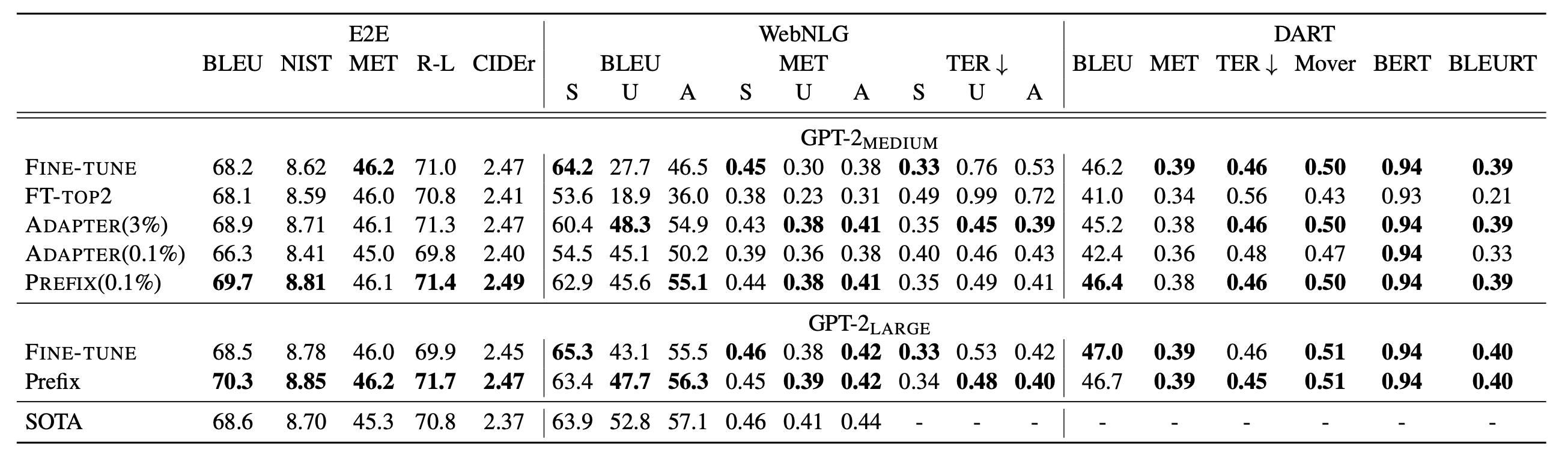
模型: GPT-2做table2text生成任务;BART做摘要任务
-
基准tuning方法
- 整体微调(fine-tuning), 只fine-tuning网络的头两层(FT-top2), adapter-tuning(adapter)
-
结果
-
在table-to-text generation任务上,prefix tuning和fine tuning在整个数据集上训练后的测试效果相近
- 任务描述:如给定table: “name: Starbucks | type: coffee shop”, 生成描述“Starbucks serves coffee.”
-
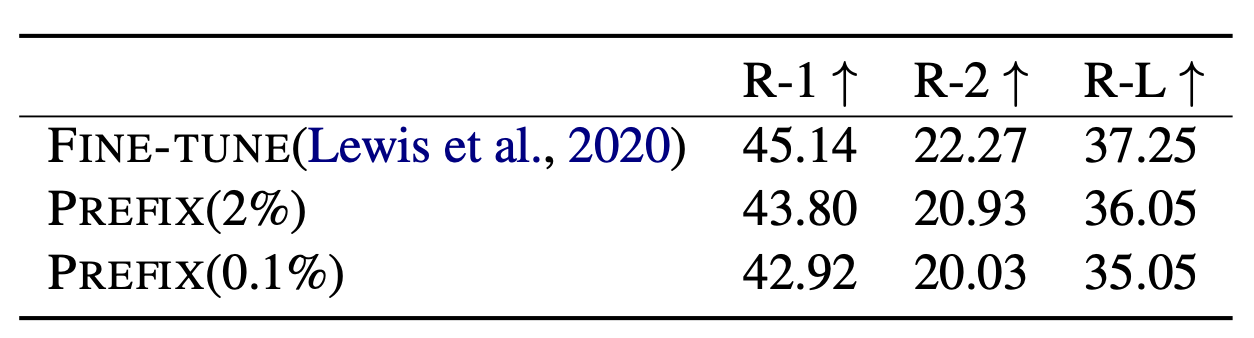
在摘要任务上,prefix tuning的效果仅比fine tuning退化了一点
-
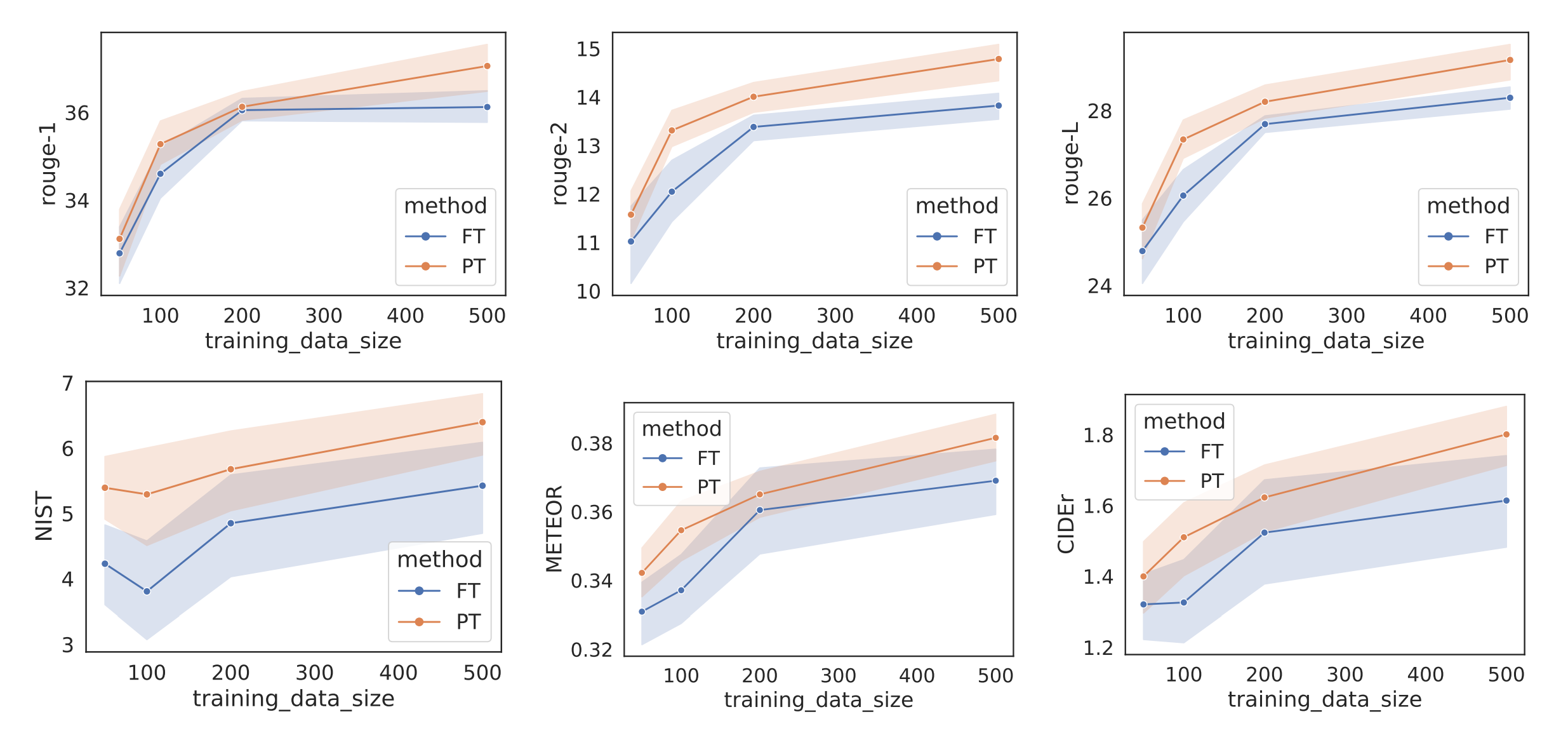
在少样本的设定下,prefix tuning在两个任务上平均效果超过了fine tuning
- 在少样本设定下,使用真实词的激活值来初始化prefix会比随机初始化显著outperform
-
对比prefix tuning和infix tuning: $[\text{prefix};x;y]$ v.s. $[x;\text{infix};y]$
-
infix tuning比prefix tuning效果略差
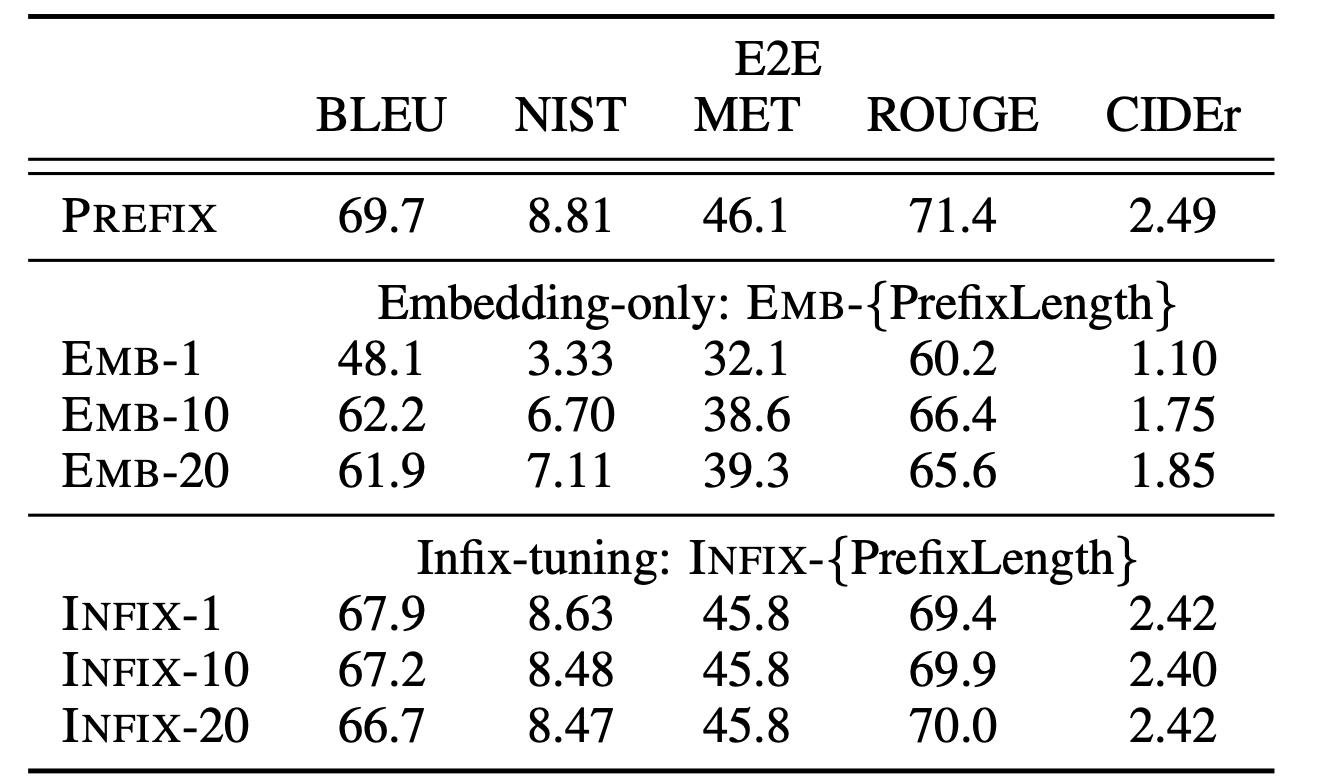
- 可能因为prefix tuning会同时影响x和y的激活情况(因为在头部),而infix tuning只会影响y的激活
-
-