
链接
论文
代码
问题描述
- GPT使用传统的微调策略没法在自然语言理解任务上取得较好结果,而通过新的调整策略,可以让大小相似的GPT在NLU上取得比BERT相近或更好的结果。
方法细节
-
思路
-
自动化地寻找连续空间中的知识模板;训练知识模板,但不fine-tune语言模型。
-
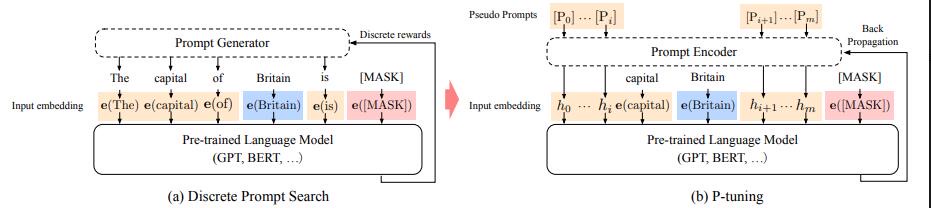
给定一个prompt $T={[P_{0:i}],x,[P_{i+1:m}]}$,传统的离散prompt模板将其映射为${e([P_{0;i}]), e(x), e([P_{i+1,m}]), e(y)}$,其中的Pi所用的词语是模型词汇表中的词。
-
P-tuning将$[P_i]$当成一个伪token(之所以叫伪token是因为后续还将进行更新),将其映射为${h_0,...,h_i,e(x),h_{i+1},...,h_m,e(y)}$
-
-
步骤
-
输入一个句子,以及预先设计的一个离散的模板:
The Disney film is good! It was [MASK].; -
对输入的template中,挑选一个(或多个)token 作为pseudo token:
The Disney film is good! [pseudo] was [MASK].-
其初始化可以直接使用原本的token embedding;

- 其中
[u1,...,u6]代表词表中的[unused1]~[unused6],也就是用几个从未见过的tokens来构成模板
- 其中
-
-
对所有的pseudo token $[P_i]$ ,传入一层LSTM,并获得每个pseudo token输出的隐状态向量 $h_i$ ($h_i$就是一个可以训练的连续的稠密的张量,从而促使模型可以找个更好的连续prompts)
-
P-tuning并不是随机初始化这些pseudo tokens然后直接训练,而是通过一个BiLSTM模型,加上一个使用ReLU作为激活函数的双层MLP,把这几个Embedding算出来,并且将这个LSTM模型设为可学习的。避免了人工构建离散的template,而让模型可以自动学习continuous embedding
-
只对Prompt部分的参数进行训练,而语言模型的参数固定不变
-
使用BiLSTM+MLP本质上也是类似prefix-tuning中的重参数化作用
-
-
-
将整个句子传入预训练语言模型层,对于pseudo token传入隐藏状态 $h_i$, 对于原始词和
[mask],则传入embedding $e_i$
-
效果
-
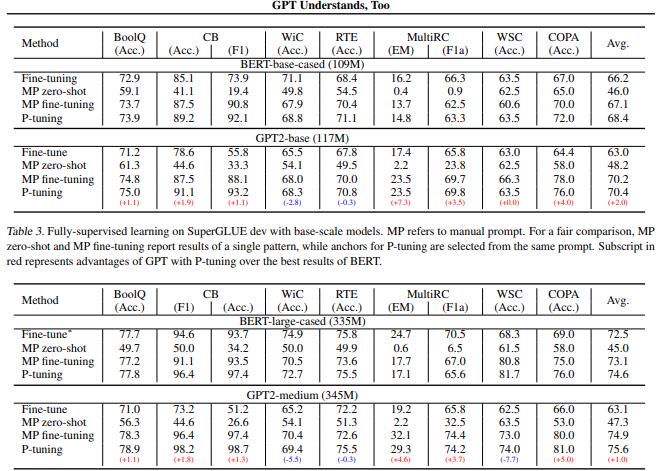
LAMA+SuperGLUE基准数据集
-
LAMA数据集,根据知识库中结构化三元组(事实)构建的完形填空类型的数据。
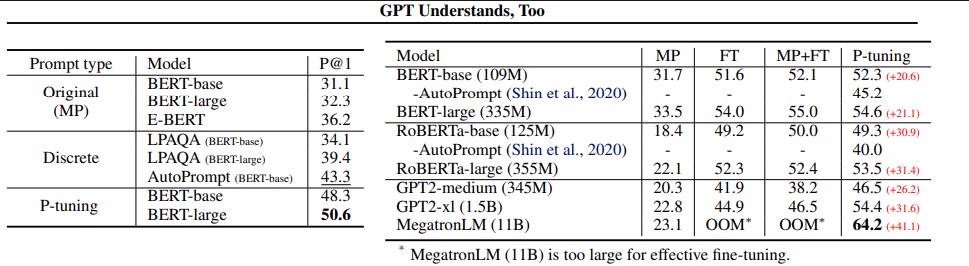
- Manual Prompt (MP): use original handcraft prompts from LAMA.(提供了人造的prompt).
- 对于具有110亿个参数的MegatronLM2,虽然微调几乎不起作用,但P-tuning仍然可以进一步提高精度
-
-
结论
- 作者发现添加少量锚标记(anchor tokens)有助于SuperGLUE的一些NLU任务。例如在prompt模板“[PRE][prompt tokens][HYP]?[prompt tokens][MASK]”中的
“?”就是一个锚节点,对性能影响很大。 - 在知识探测任务中:语言模型可以仅通过找到更好的prompt,不进行微调,就能捕捉到更多的知识。
- P-tuning可以有效的提高BERT和GPT模型在NLU任务上的性能。并且使用P-tuning,可以让相似代销的GPT2实现比bert模型相当的甚至更好的结果,这个发现颠覆普遍认为的——双向模型比单向模型在NLU任务中表现的更好。
- 当预训练模型足够大的时候,我们的设备可能无法finetune整个模型,而P-tuning可以选择只优化几个Token的参数,因为优化所需要的显存和算力都会大大减少,所以P-tuning实则上给了我们一种在有限算力下调用大型预训练模型的思路。
结论部分大部分引用参考笔记中的总结。
问题
- 当预训练语言模型的参数量低于100亿时,Prompt-tuning会比传统的Fine-tuning差;
- 像序列标注等对推理和理解要求高的任务,prompt-tuning效果会变差;
应用
- 在HUAWEI推出的盘古-$\alpha$模型中,P-tuning也被用于其的微调框架中